
onevision-encoder
Collection
4 items • Updated • 6
YAML Metadata Warning:empty or missing yaml metadata in repo card
Check out the documentation for more information.
onevision-encoder-large-lang-tf57transformers 5.7+ idiomatic variant of
lmms-lab-encoder/onevision-encoder-large-lang. Weights are byte-identical to the upstream model (samesafetensorsSHA-256). Onlymodeling_onevision_encoder.pyandconfig.json(transformers_versionfield) differ.Why this variant
Upstream
modeling_onevision_encoder.pyis written against thetransformers 4.xAPI surface and does not load correctly undertransformers >= 5.0:
_supports_flash_attn_2was renamed to_supports_flash_attn.- The v5 fast-init / meta-tensor path skips re-initialization of
persistent=Falsebuffers, leavingVideoRotaryEmbeddingSplit466.inv_freq_{t,h,w}filled with uninitialized memory. RoPE then produces garbage and downstream attention diverges (max diff up to 700+ vs upstream).add_start_docstrings*/replace_return_docstringsdecorators are removed in v5.- Manual eager-only attention is replaced by the v5
ALL_ATTENTION_FUNCTIONSinterface dispatching acrosseager,sdpa,flash_attention_2,flex_attention.v5-only notice
This variant requires
transformers >= 5.7.0and will not load undertransformers 4.x. Use the upstream model dir for v4 environments.Lang-specific surface (vs
large)Same backbone, but the
langvariant exposes the encoder for language-aligned multimodal callers:
forward(..., patch_positions=...)accepts an explicit(batch_size, seq_len, 3)[t, h, w]per-patch position tensor (mutually exclusive with the default grid path).VideoRotaryEmbeddingSplit466.forward_from_positions(patch_positions)computes RoPE frequencies directly from those positions.apply_rotary_pos_embcastscos/sintoq.dtypeimmediately rather than computing in fp32, to preserve FlashAttention's dtype contract under bf16/fp16.- No pooling head:
pooler_outputisNone.Diff vs upstream
File Change model.safetensorsunchanged (byte-identical) config.jsontransformers_version: 4.57.3->5.7.0configuration_onevision_encoder.pyunchanged preprocessor_config.jsonunchanged modeling_onevision_encoder.pyfull v5-idiom rewrite (same as large) plus the lang-specific surface above.Usage
from transformers import AutoModel model = AutoModel.from_pretrained( "path/to/onevision-encoder-large-lang-tf57", trust_remote_code=True, ) # default attn_implementation = "flash_attention_2" (set in config.json) # default grid path out = model(pixel_values=images) # explicit per-patch positions (lang-only) out = model(pixel_values=images, patch_positions=patch_positions)Override the default if you need a different backend:
model = AutoModel.from_pretrained(..., attn_implementation="sdpa") # supported: "flash_attention_2" (default), "sdpa", "eager", "flex_attention"Dtype contract: weights are saved in
bfloat16. The defaultflash_attention_2backend requiresfp16/bf16inputs. If you must usefp32, override withattn_implementation="sdpa"or"eager".Numerical note (lang variant): Unlike the
largevariant, attention backends are NOT numerically equivalent inbf16for this model —eagerandflash_attention_2/sdpadiffer inmax_diffup to several hundred in absolute value (mean diff < 0.1, std preserved). This is due to the lang variant intentionally keeping RoPEcos/sininq.dtype(bf16) instead of upcasting tofp32like thelargevariant. The model still trains/serves correctly on any backend, but if you need strict numerical reproducibility against the upstream model, useattn_implementation="eager"inbf16or any backend infp32.Tested with
transformers==5.7.0,torch>=2.4,flash-attn>=2.7.Equivalence verification
Cross-version (upstream tf 4.57.3 vs this tf 5.7.0) on 11 input shapes (single image / multi-frame video / batched / non-square /
patch_positions):
dtype attn result fp32 eager bit-identical (max_diff = 0.0 across all __lhstensors;__poolisNonefor both)bf16 eager bit-identical (max_diff = 0.0 across all __lhstensors;__poolisNonefor both)Plus 7 v5-only scenario tests, all PASSED:
- eager vs sdpa equivalence (max=9.2e-3)
- save_pretrained then from_pretrained bit-identical round-trip
- cpu vs cuda equivalence (max=3.5e-3)
- fp32/bf16/fp16 dtype preservation
- gradient flow
- runtime
_attn_implementationswitchfrom_pretrainedidempotency (two loads bit-identical)Plus real-input end-to-end tests on a real JPEG (1332x725) and a real MP4 (decord, 4 frames @ 512x512), preprocessed through
AutoImageProcessor(CLIPImageProcessor):
path result image: PIL -> processor -> model fwd finite, lhs=(1,1024,1024) video: decord -> 5D (1,3,4,448,448) -> model fwd finite, lhs=(1,4096,1024) model-only equivalence on identical pixel_values (v4 vs v5) bit-identical (max_diff = 0.0 on image+video) Note: Raw
pixel_valuesfromCLIPImageProcessordiffer by ~1e-2 between transformers 4.57.3 and 5.7.0 due to upstream resize/normalize changes intransformersitself (independent of this variant). When the same pixel_values are fed to both versions, this model is bit-identical.Reproduce with
tools/upgrade_v5/run_all.shfrom the OneVision-Encoder repo.Changelog
- tf57: full v5-idiom rewrite; weights unchanged.
The original model card from upstream follows.
Transformers Version Compatibility:
- ✅
transformers==4.57.3(Recommended): Works withAutoModel.from_pretrained()- ⚠️
transformers>=5.0.0: Not currently supported. We are actively working on a fix.
Note on Inputs: While the model is pre-trained with the configurations below, it supports dynamic native resolution and arbitrary frame counts during inference:
- Pre-training Image Base: 448×448
- Pre-training Video Base: 224×224 (256 tokens/frame)
- Inference: Supports variable resolutions and frame lengths.
from transformers import AutoModel, AutoImageProcessor
from PIL import Image
import torch
# Load model and preprocessor
model = AutoModel.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large-lang",
trust_remote_code=True,
attn_implementation="flash_attention_2"
).to("cuda").eval()
preprocessor = AutoImageProcessor.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large-lang",
trust_remote_code=True
)
# Image inference: [B, C, H, W]
image = Image.open("path/to/your/image.jpg") # Replace with your image path
pixel_values = preprocessor(images=image, return_tensors="pt")["pixel_values"].to("cuda")
with torch.no_grad():
outputs = model(pixel_values)
# outputs.last_hidden_state: [B, num_patches, hidden_size]
# outputs.pooler_output: [B, hidden_size]
# Video inference: [B, C, T, H, W] with patch_positions
num_frames, target_frames = 16, 64
patch_size = 14
# Load video frames and preprocess each frame (replace with your video frame paths)
frames = [Image.open(f"path/to/frame_{i}.jpg") for i in range(num_frames)]
video_pixel_values = preprocessor(images=frames, return_tensors="pt")["pixel_values"]
# Reshape from [T, C, H, W] to [B, C, T, H, W]
video = video_pixel_values.unsqueeze(0).permute(0, 2, 1, 3, 4).to("cuda")
# Build patch_positions for temporal sampling: [B, num_frames * frame_tokens, 3]
frame_pos = torch.linspace(0, target_frames - 1, num_frames).long().cuda() # [T]
grid_h, grid_w = video.shape[-2] // patch_size, video.shape[-1] // patch_size # patch grid
frame_tokens = grid_h * grid_w
t_positions = frame_pos[:, None].repeat(1, frame_tokens).reshape(-1) # [T * frame_tokens]
h_positions = torch.arange(grid_h, device="cuda").repeat_interleave(grid_w)
h_positions = h_positions.repeat(num_frames) # [T * frame_tokens]
w_positions = torch.arange(grid_w, device="cuda").repeat(grid_h)
w_positions = w_positions.repeat(num_frames) # [T * frame_tokens]
patch_positions = torch.stack([t_positions, h_positions, w_positions], dim=-1).unsqueeze(0)
# patch_positions example (256 tokens per frame, 16x16 patch grid):
# Each row is [t, h, w].
# First 4 patches of frame 0 (t=0):
# patch_positions[0, 0:4, :] -> [[0, 0, 0], [0, 0, 1], [0, 0, 2], [0, 0, 3]]
# First 4 patches of frame 1 (t=4):
# patch_positions[0, 256:260, :] -> [[4, 0, 0], [4, 0, 1], [4, 0, 2], [4, 0, 3]]
with torch.no_grad():
outputs = model(video, patch_positions=patch_positions)
git clone [https://github.com/EvolvingLMMs-Lab/OneVision-Encoder.git](https://github.com/EvolvingLMMs-Lab/OneVision-Encoder.git)
cd OneVision-Encoder
pip install -e .
from onevision_encoder import OneVisionEncoderModel, OneVisionEncoderConfig
from transformers import AutoImageProcessor
model = OneVisionEncoderModel.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large-lang",
trust_remote_code=True,
attn_implementation="flash_attention_2"
).to("cuda").eval()
preprocessor = AutoImageProcessor.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large-lang",
trust_remote_code=True
)
Training on a mixed dataset of 740K samples from LLaVA-OneVision and 800K samples from LLaVA-Video SFT. The training pipeline proceeds directly to Stage 2 fine-tuning.
We adopt a streamlined native-resolution strategy inspired by LLaVA-OneVision: when the input frame resolution matches the model's native input size, it is fed directly—without tiling or cropping—to evaluate the ViT's capability to handle true native resolution and arbitrary frame sequences.
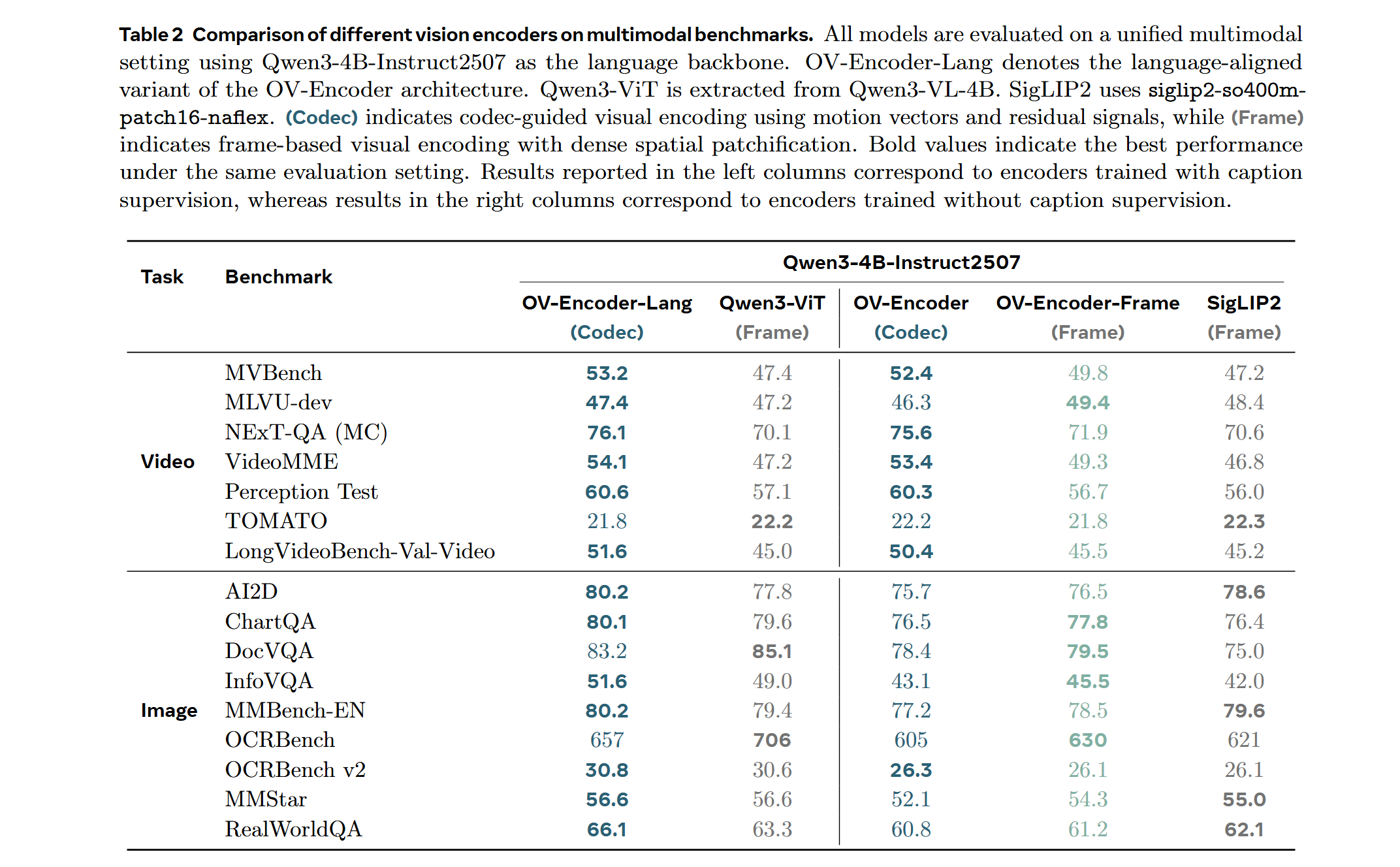
| Property | Value |
|---|---|
| Model Type | LLM-Aligned Vision Transformer (ViT) |
| Architecture | HEVC-Style / Codec-Like Vision Transformer |
| Input Paradigm | Codec-Style (Sparse Patch / Dense Frame) |
| Resolution Strategy | True Native Resolution (Dynamic, No Tiling) |
| Temporal Context | Arbitrary Frame Count (Variable Length Support) |
| Hidden Size | 1024 |
| Intermediate Size | 4096 |
| Number of Layers | 24 |
| Number of Attention Heads | 16 |
| Patch Size | 14 |
| Positional Encoding | 3D RoPE (4:6:6 split for T:H:W) |
| Normalization | Layer Normalization |
| Activation Function | GELU |
| License | Apache 2.0 |