
Infinity-Parser2
Collection
Multimodal Synthetic Dataset and Multi-Task Reinforcement Learning Document Parser • 4 items • Updated
YAML Metadata Warning:empty or missing yaml metadata in repo card
Check out the documentation for more information.
![]()
💻 Github | 📊 Dataset | 📄 Paper (coming soon...) | 🚀 Demo
We are excited to release Infinity-Parser2, our latest flagship document understanding model. We offer two distinct variants to address diverse deployment constraints: Infinity-Parser2-Pro, optimized for maximum accuracy in precision-critical tasks, achieves state-of-the-art results on olmOCR-Bench (87.6%) and ParseBench (74.3%), surpassing frontier models including DeepSeek-OCR-2, PaddleOCR-VL-1.5, and MinerU-2.5. Infinity-Parser2-Flash, engineered for low-latency inference, delivers a 3.68x speedup over our previous Infinity-Parser-7B model. With significant upgrades to both our data engine and multi-task reinforcement learning approach, the model consolidates robust multi-modal parsing capabilities into a unified architecture, unlocking brand-new zero-shot capabilities across a wide range of real-world business scenarios.
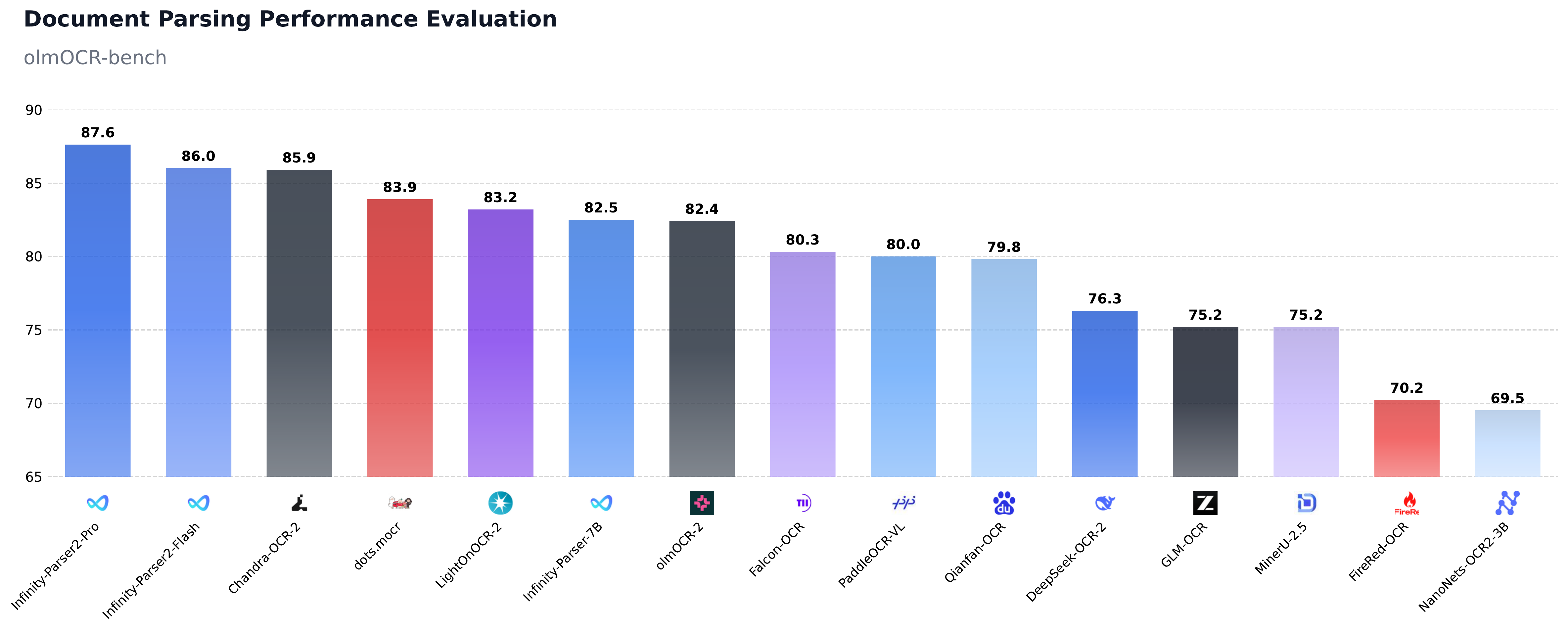
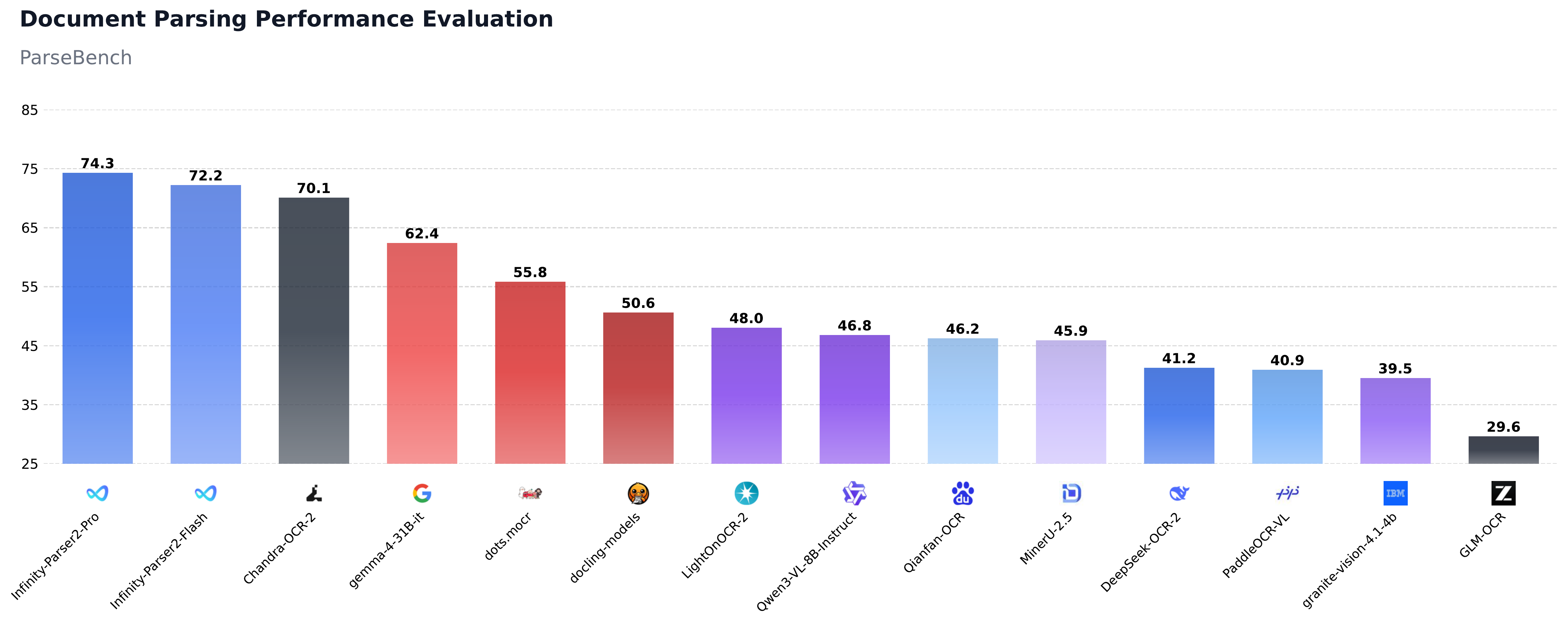
| Task | Infinity-Parser2-Pro | Infinity-Parser2-Flash | PaddleOCR-VL-1.5 | DeepSeek-OCR-2 | MinerU-2.5 | Gemini-3-Pro |
|---|---|---|---|---|---|---|
| Document Parsing | ||||||
| olmOCR-bench | 87.6 | 86.0 | 80.0† | 76.3 | 75.2 | - |
| ParseBench | 74.3 | 72.2 | 40.9† | 41.2 | 45.9 | 69.1‡ |
| OmniDocBench-v1.6 | 93.95 | 91.98 | 94.87 | 90.17 | 92.98 | 92.85 |
| Layout Analysis (mIoU) | ||||||
| DocLayNet | 64.93* | 64.97* | 71.05* | 45.62* | 67.74* | - |
| D4LA | 52.41* | 46.05* | 50.21* | 33.03* | 51.62* | - |
| OmniDocBench-v1.5-Layout | 74.56* | 73.07* | 74.80* | 55.28* | 76.28* | - |
| Element Parsing | ||||||
| OmniDocBench-v1.5-TextBlock | 93.66 | 93.53 | 94.97* | 84.13* | 86.00 | - |
| PubTabNet (val) | 94.76 | 92.41 | 84.60 | 89.53* | 89.07 | 91.40 |
| UniMERNet | 97.7 | 96.5 | 95.8* | 79.8* | 96.5 | 96.4 |
| Chart Parsing | ||||||
| Chart2Table | 80.45 | 80.49 | 86.2* | - | - | - |
| Chart2Json | 73.69 | 67.66 | - | - | - | - |
| Chemical Formula Parsing | ||||||
| CoSyn_Chemical | 71.48 | 62.08 | - | 52.16* | - | - |
| Document VQA | ||||||
| DocVQA (val) | 96.43 | 93.16 | - | 43.42* | - | 93.68* |
| InfoVQA (val) | 86.26 | 75.94 | - | 22.07* | - | 85.24* |
| General Multimodal Understanding | ||||||
| AI2D | 88.89 | 79.53 | - | 37.66* | - | 91.87* |
| MathVista (testmini) | 71.4 | 59.5 | - | - | - | 81.8* |
| MMBench-EN (dev) | 87.54 | 77.92 | - | - | - | 90.29* |
| MMBench-CN (dev) | 86.43 | 75.77 | - | - | - | 90.98* |
| MMMU (val) | 61.89 | 45.89 | - | - | - | 56.00* |
| MMStar | 69.66 | 57.13 | - | - | - | 83.78* |
| OCRBench | 86.20 | 81.60 | - | 47.20* | - | 89.30* |
Note: '*' denotes results evaluated using our internal evaluation tools. Results marked with '†' are from PaddleOCR-VL. '‡' denotes results from the Gemini-3.1-Pro.
If you are looking for a minimal script to parse a single image to Markdown using the native transformers library, here is a simple snippet:
from PIL import Image
import torch
from transformers import AutoModelForImageTextToText, AutoProcessor
from qwen_vl_utils import process_vision_info
# Load the model and processor
model = AutoModelForImageTextToText.from_pretrained(
"infly/Infinity-Parser2-Pro",
torch_dtype="float16",
device_map="auto",
)
processor = AutoProcessor.from_pretrained("infly/Infinity-Parser2-Pro")
# Build the messages for the model
pil_image = Image.open("demo_data/demo.png").convert("RGB")
min_pixels = 2048 # 32 * 64
max_pixels = 16777216 # 4096 * 4096
prompt = """
- Extract layout information from the provided PDF image.
- For each layout element, output its bbox, category, and the text content within the bbox.
- Bbox format: [x1, y1, x2, y2].
- Allowed layout categories: ['header', 'title', 'text', 'figure', 'table', 'formula', 'figure_caption', 'table_caption', 'formula_caption', 'figure_footnote', 'table_footnote', 'page_footnote', 'footer'].
- Text extraction and formatting:
1) For 'figure', the text field must be an empty string.
2) For 'formula', format text as LaTeX.
3) For 'table', format text as HTML.
4) For all other categories (e.g., text, title), format text as Markdown.
- The output text must be exactly the original text from the image, with no translation or rewriting.
- Sort all layout elements in human reading order.
- Final output must be a single JSON object.
"""
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": pil_image,
"min_pixels": min_pixels,
"max_pixels": max_pixels,
},
{"type": "text", "text": prompt},
],
}
]
chat_template_kwargs = {"enable_thinking": False}
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True, **chat_template_kwargs
)
image_inputs, _ = process_vision_info(messages, image_patch_size=16)
inputs = processor(
text=text,
images=image_inputs,
do_resize=False,
padding=True,
return_tensors="pt",
)
# Move all tensors to the same device as the model
inputs = {
k: v.to(model.device) if isinstance(v, torch.Tensor) else v
for k, v in inputs.items()
}
# Generate the response
generated_ids = model.generate(
**inputs,
max_new_tokens=32768,
temperature=0.0,
top_p=1.0,
)
# Strip input tokens, keeping only the newly generated response
generated_ids_trimmed = [
out_ids[len(in_ids) :]
for in_ids, out_ids in zip(inputs["input_ids"], generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
For bulk processing, advanced features, or an end-to-end PDF parsing pipeline, we recommend using our infinity_parser2 wrapper.
# Create a Conda environment (Optional)
conda create -n infinity_parser2 python=3.12
conda activate infinity_parser2
# Install PyTorch (CUDA). Find the proper version at https://pytorch.org/get-started/previous-versions based on your CUDA version.
pip install torch==2.10.0 torchvision==0.25.0 torchaudio==2.10.0 --index-url https://download.pytorch.org/whl/cu128
# Install FlashAttention (FlashAttention-2 is recommended by default)
# Standard install (compiles from source, ~10-30 min):
pip install flash-attn==2.8.3 --no-build-isolation
# Faster install: download wheel from https://github.com/Dao-AILab/flash-attention/releases. Then run: pip install /path/to/<wheel_filename>.whl
# For Hopper GPUs (e.g. H100, H800), we recommend FlashAttention-3 instead. See: https://github.com/Dao-AILab/flash-attention
# NOTE: The code will prioritize detecting FlashAttention-3. If not found, it falls back to FlashAttention-2.
# Install vLLM
# NOTE: you may need to run the command below to resolve triton and numpy conflicts before installing vllm.
# pip uninstall -y pytorch-triton opencv-python opencv-python-headless numpy && rm -rf "$(python -c 'import site; print(site.getsitepackages()[0])')/cv2"
pip install vllm==0.17.1
Install from PyPI
pip install infinity_parser2
Install from source code
git clone https://github.com/infly-ai/INF-MLLM.git
cd INF-MLLM/Infinity-Parser2
pip install -e .
The parser command is the fastest way to get started.
# NOTE: The Infinity-Parser2 model will be automatically downloaded on the first run.
# Parse a PDF (outputs Markdown by default)
parser demo_data/demo.pdf
# Parse an image
parser demo_data/demo.png
# Batch parse multiple files
parser demo_data/demo.pdf demo_data/demo.png -o ./output
# Parse an entire directory
parser demo_data -o ./output
# Output raw JSON with layout bboxes
parser demo_data/demo.pdf --output-format json
# Convert to Markdown directly
parser demo_data/demo.png --task doc2md
# View all options
parser --help
# NOTE: The Infinity-Parser2 model will be automatically downloaded on the first run.
from infinity_parser2 import InfinityParser2
parser = InfinityParser2()
# Parse a single file (returns Markdown)
result = parser.parse("demo_data/demo.pdf")
print(result)
# Parse multiple files (returns list)
results = parser.parse(["demo_data/demo.pdf", "demo_data/demo.png"])
# Parse a directory (returns dict)
results = parser.parse("demo_data")
Output formats:
| task_type | Description | Default Output |
|---|---|---|
doc2json |
Extract layout elements with bboxes (default) | Markdown |
doc2md |
Directly convert to Markdown | Markdown |
custom |
Use your own prompt | Raw model output |
# doc2json: get raw JSON with bbox coordinates
result = parser.parse("demo_data/demo.pdf", output_format="json")
# doc2md: direct Markdown conversion
result = parser.parse("demo_data/demo.pdf", task_type="doc2md")
# Custom prompt
result = parser.parse("demo_data/demo.pdf", task_type="custom",
custom_prompt="Please transform the document's contents into Markdown format.")
# Batch processing with custom batch size
result = parser.parse("demo_data", batch_size=8)
# Save results to directory
parser.parse("demo_data/demo.pdf", output_dir="./output")
Backends:
Infinity-Parser2 supports three inference backends. By default it uses the vLLM Engine (offline batch inference).
# vLLM Engine (default) — offline batch inference
parser = InfinityParser2(
model_name="infly/Infinity-Parser2-Pro",
backend="vllm-engine", # default
tensor_parallel_size=2,
)
# Transformers — local single-GPU inference
parser = InfinityParser2(
model_name="infly/Infinity-Parser2-Pro",
backend="transformers",
device="cuda",
torch_dtype="bfloat16", # "float16" or "bfloat16"
)
# vLLM Server — online HTTP API (start server first)
parser = InfinityParser2(
model_name="infly/Infinity-Parser2-Pro",
backend="vllm-server",
api_url="http://localhost:8000/v1/chat/completions",
api_key="EMPTY",
)
To start a vLLM server:
vllm serve infly/Infinity-Parser2-Pro \
--trust-remote-code \
--reasoning-parser qwen3 \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.85 \
--max-model-len 65536 \
--mm-encoder-tp-mode data \
--mm-processor-cache-type shm \
--enable-prefix-caching
For more details, please refer to the official guide.
Infinity-Parser2 has several known limitations to consider. It primarily supports English and Chinese documents, and performance degrades when processing multilingual content. Accuracy may also be reduced when parsing charts with complex layouts, as well as documents containing multi-oriented elements such as table rotated at varying angles. Additionally, the model does not capture fine-grained text formatting (e.g., bold, italic, strikethrough) and exhibits suboptimal multimodal instruction-following capability, meaning it may not always reliably follow complex multi-step visual instructions.
We would like to thank Qwen3.5, ms-swift, VeRL, lmms-eval, olmocr, PaddleOCR-VL, MinerU, dots.ocr, Chandra-OCR-2 for providing dataset, code and models.
This model is licensed under apache-2.0.