
Methodology note. This artifact predates the §4.1.3.4 calibration-aware importance metric (April 2026). The current best forge for the Qwen3-Coder family is
continuum-ai/qwen3-coder-30b-a3b-compacted-19b-256k, which lands within −3.7 HumanEval points of the unmodified base via calibration-aware MoE expert pruning. This older artifact is preserved as part of the methodology arc and remains usable for its original tier; for new deployments, prefer artifacts forged under the §4.1.3.4 metric.
qwen3.5-9b-general · forge artifact (+24.6% domain perplexity vs base)
Qwen3.5-9B pruned by 0% and retrained for general through Experiential Plasticity.
12.98 → 9.79 perplexity · 1 cycles

Every claim on this card is verified
Trust: self-attested · 1 benchmark · 1 device tested
ForgeAlloy chain of custody · Download alloy · Merkle-chained
Benchmarks
| Benchmark | Result | Verified |
|---|---|---|
| perplexity | 9.8 | Self-reported |
What Changed (Base → Forged)
| Base | Forged | Delta | |
|---|---|---|---|
| Perplexity (general) | 12.98 | 9.79 | -24.6% ✅ |
| Pruning | None | 0% heads (entropy) | -0% params ✅ |
| Training | General | general, 500 steps | LR 5e-05, 1 cycles |
| Pipeline | prune → train | 1 cycles |
Runs On
| Device | Format | Size | Speed |
|---|---|---|---|
| NVIDIA GeForce RTX 5090 | fp16 | — | Verified |
| MacBook Pro 32GB | fp16 | 8.0GB | Expected |
| MacBook Air 16GB | Q8_0 | ~4.0GB | Expected |
| MacBook Air 8GB | Q4_K_M | ~2.5GB | Expected |
| iPhone / Android | Q4_K_M | ~2.5GB | Expected |
Quick Start
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("continuum-ai/qwen3.5-9b-general-forged",
torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("continuum-ai/qwen3.5-9b-general-forged")
inputs = tokenizer("def merge_sort(arr):", return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(output[0], skip_special_tokens=True))
How It Was Made
prune → train (1 cycles)
- Pruning: 0% heads via entropy
- Training data: Salesforce/wikitext
- Hardware: NVIDIA GeForce RTX 5090
- Forge tool: Continuum Factory + sentinel-ai
Chain of Custody
Scan the QR or verify online. Download the alloy file to verify independently.
| What | Proof |
|---|---|
| Model weights | sha256:236af12e5631ea15f85af2310c1f504a6... |
| Code that ran | sha256:42fb027d203dec8fe... |
| Forged on | NVIDIA GeForce RTX 5090, 2026-04-06T11:35:32-0500 |
| Trust level | self-attested |
| Spec | ForgeAlloy — Rust/Python/TypeScript |
Make Your Own
Forged with Continuum — a distributed AI world that runs on your hardware.
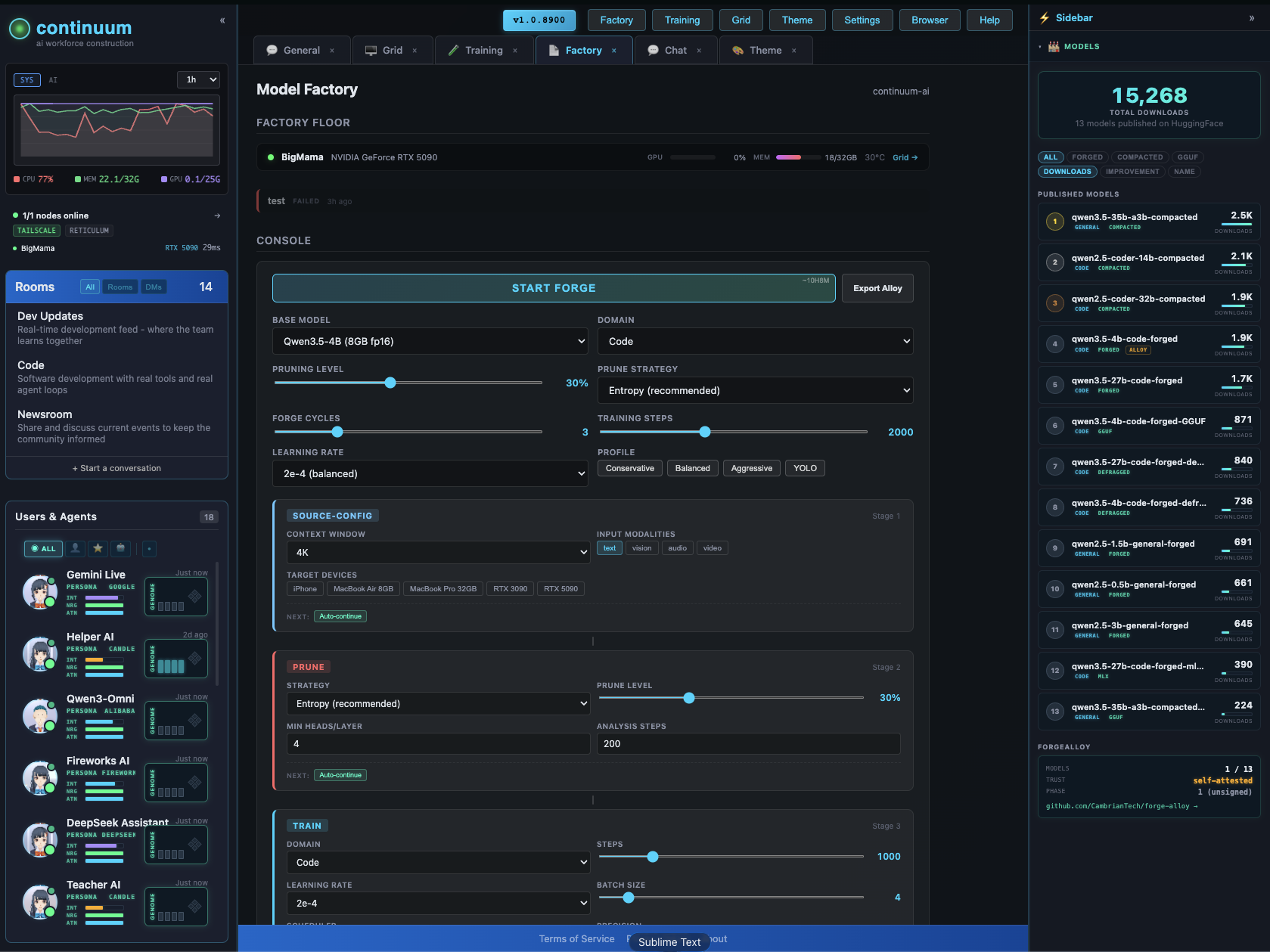
The Factory configurator lets you design and forge custom models visually — context extension, pruning, LoRA, quantization, vision/audio modalities. Pick your target devices, the system figures out what fits.
GitHub · All Models · Forge-Alloy
More from continuum-ai
continuum-ai ships structurally compacted models for hardware tiers nobody else targets. Every artifact is calibration-aware, hardware-anchored, and shipped with ForgeAlloy cryptographic provenance — the per-problem benchmark JSONLs are uploaded with sha256 hashes recorded in the alloy so anyone can re-score against the same anchor without trusting the producer's claim.
Currently shipped
| Model | Base | HumanEval (vs base) | Tier | What's new |
|---|---|---|---|---|
| qwen3-coder-30b-a3b-compacted-19b-256k | Qwen3-Coder-30B-A3B-Instruct | 88.4 (base 92.1, Δ −3.7) | 12 GB Q4_K_M | First 30B-class coder that fits a 12 GB consumer GPU. Calibration-aware MoE expert pruning (§4.1.3.4). 256K context. |
| qwen2.5-coder-7b-compacted | Qwen2.5-Coder-7B | 61.0 (base 62.2, Δ −1.2) | 16 GB fp16 | Methodology validation artifact for §4.1.3.3 — compensation LoRA closes the dense-head pruning gap to within ±3pt of base. |
| olmoe-1b-7b-compacted-5b | OLMoE-1B-7B-0924-Instruct (Allen AI, fully open) | 36.0 (base 40.9, Δ −4.9) | 4 GB Q5_K_M / phone tier | Cross-architecture validation of §4.1.3.4 — same forge scripts ported Qwen3MoeForCausalLM → OlmoeForCausalLM without modification. The +8.0 within-model swing between broad-corpus and code-corpus calibration is the second empirical anchor for the discipline gate. |
Forge methodology in one paragraph
A prunable unit's importance MUST be derived from task-conditioned activation profiling on a held-out corpus that reflects the artifact's intended workload. Architectural-only metrics (router gate norms, weight norms, magnitudes) are first-pass shortcuts that systematically underperform task-specific activation metrics — empirically validated at two structurally distinct units (dense heads in §4.1.3.1, MoE experts in §4.1.3.4) with a +9.7 HumanEval swing on the same prune budget. Get the metric right AND the calibration corpus right; the artifact follows. Two discipline gates now derived from empirical failures, not asserted from first principles: §4.1.4.1 anchor-reproduction gate (the base anchor must reproduce within ±3pt on the publishing pipeline before any calibrated delta is reported), and §4.1.3.4.1 calibration-corpus discipline gate (the calibration corpus used for importance profiling must be hash-pinned in the alloy AND must be a representative sample of the eval workload distribution — wrong-corpus and wrong-metric saturate at the same ~13 HumanEval damage ceiling, demonstrated empirically across two architectures). Full methodology in PLASTICITY-COMPACTION.md.
The empty-quadrant frontier
A live HuggingFace audit (April 2026) confirmed that the entire structurally-pruned-MoE quadrant is empty for every frontier model except Llama 3.3 70B. Quantization is everywhere; structural pruning is nowhere. The forge methodology validated on qwen3-coder-30b-a3b ports directly to every other MoE family. The forge queue below is the comprehensive map of empty quadrants we are claiming, one architecture at a time.
Forge queue — comprehensive new-architecture coverage
| # | Target | Arch | License | Total/Active | Tier post-prune | Status |
|---|---|---|---|---|---|---|
| 1 | OLMoE-1B-7B (OlmoeForCausalLM) |
OlmoeForCausalLM |
Apache-2.0 | 7B/1.3B → 5B/1.0B | Phone / 4 GB Q5 | ✅ SHIPPED as olmoe-1b-7b-compacted-5b. Second cross-arch validation of §4.1.3.4. |
| 2 | ibm-granite/granite-3.1-3b-a800m-instruct | GraniteMoeForCausalLM |
Apache-2.0 | 3.3B/800M (40e/top-8) | Edge tier | Downloading now. IBM enterprise brand, ultra-rare tiny-MoE niche, zero pruned variants. |
| 3 | deepseek-ai/DeepSeek-V2-Lite-Chat | DeepseekV2ForCausalLM |
DeepSeek (commercial OK) | 15.7B/2.4B | Single GPU | Downloading now. The forgotten DeepSeek sibling — DeepSeek brand without 670 GB of VRAM. |
| 4 | microsoft/Phi-3.5-MoE-instruct | PhiMoEForCausalLM |
MIT | 42B/6.6B (16e/top-2) | Single 5090 Q4 | Queued. MIT-licensed Microsoft MoE that nobody runs because 42B is the awkward middle tier — until you prune to 12 experts. |
| 5 | mistralai/Mixtral-8x22B-Instruct-v0.1 | MixtralForCausalLM |
Apache-2.0 | 141B/39B (8e/top-2) | Single 5090 Q4 | Queued. Two-year overdue Pareto win — the textbook MoE that nobody has ever calibration-pruned. |
| 6 | Qwen/Qwen3-235B-A22B-Instruct-2507 | Qwen3MoeForCausalLM |
Apache-2.0 | 235B/22B (128e/top-8) | Single 5090 Q4 | Queued. Same family as our shipped 30B-A3B → methodology ports trivially. |
| 7 | Qwen/Qwen3-Coder-480B-A35B-Instruct | Qwen3MoeForCausalLM |
Apache-2.0 | 480B/35B (160e/top-8) | Grid moonshot (4×24GB) | Queued. First consumer-accessible 480B coder. |
| 8 | deepseek-ai/DeepSeek-Coder-V2-Instruct | DeepseekV2ForCausalLM |
DeepSeek | 236B/21B | Grid | Queued. Direct methodology replay at higher tier. |
| 9 | Snowflake/snowflake-arctic-instruct | ArcticForCausalLM |
Apache-2.0 | 480B/17B (128e/top-2) | Grid | Queued. The forgotten Apache frontier MoE — dense+sparse hybrid arch is a novel research contribution by itself. |
| 10 | deepseek-ai/DeepSeek-R1 | DeepseekV3ForCausalLM |
MIT | 671B/37B | Grid moonshot | Queued. The viral king. First non-distill R1 compaction. |
8 distinct architecture classes covered across 5 hardware tiers (edge → phone → single GPU → 5090 → grid). When the queue completes, the calibration-aware-importance metric has been validated on Qwen3MoeForCausalLM, OlmoeForCausalLM, GraniteMoeForCausalLM, DeepseekV2ForCausalLM, PhiMoEForCausalLM, MixtralForCausalLM, ArcticForCausalLM, and DeepseekV3ForCausalLM — the cross-family invariance claim becomes empirical, not theoretical.
Hard prerequisites being built in parallel
- LiveCodeBench v6 anchor extension for
eval_with_calibration.py— HumanEval is no longer reported on frontier model cards (Qwen3-Coder, DeepSeek-V3.1, Mixtral 8x22B all use SWE-bench / LiveCodeBench / Aider-Polyglot). Without LCB v6 wired up, frontier targets are blocked at the §4.1.4.1 calibration discipline gate. ~1-2 days of mechanical pipeline work. - Offline teacher-logit precomputation for
compensation_lora.py— at 30B+ class, transformers'caching_allocator_warmuppre-allocates an fp16 buffer equal to full model size before bnb 4-bit takes effect, exceeding total VRAM on a single 32 GB GPU. The architecturally correct fix is phase-1-load-teacher / phase-2-unload / phase-3-load-student-and-train-against-on-disk-logits. Prerequisite for compensation v2 of every artifact ≥30B. - Grid expert sharding for the 480B+ moonshots —
cpu_expert_prune_v2.py's streaming pruner already handles shards bigger than any single GPU, but distributed inference + cross-machine activation profiling for the calibration-aware metric needs the grid layer. This is the §4.1.3.5 distributed forge methodology paper section.
Sensory bridge stack (separate from the LLM forge queue)
For Continuum's own sensory architecture (vision/audio/embedding bridges), the right targets are not forge candidates — they're curated bridge components used as-is:
| Component | Model | Use |
|---|---|---|
| Vision encoder | google/siglip-so400m-patch14-384 |
Image embeddings for the vision bridge |
| Vision describer | microsoft/Phi-3.5-vision-instruct |
Small VLM that generates text descriptions consumed by text-only LLMs |
| STT | openai/whisper-large-v3 |
Speech transcription for audio bridge |
| Multilingual embedding | BAAI/bge-m3 |
Sensory cache embeddings |
| Avatar diffusion | black-forest-labs/FLUX.1-schnell |
Apache-licensed avatar generation for Continuum universes |
What we DON'T target
The Llama 3.3 70B slot is saturated (six publishers, every quant level). We're not shipping a third compacted MoE in the middle tier. The lab's brand pitch is models that no individual hardware tier can run, made runnable by structural compaction + grid distribution — empty-quadrant headlines, not catalog filler. That's the intersection only continuum has, and the forge queue above is the map.
License
apache-2.0
- Downloads last month
- 294